arXiv:2603.20854 Download PDF Models on HuggingFace Tokenizer
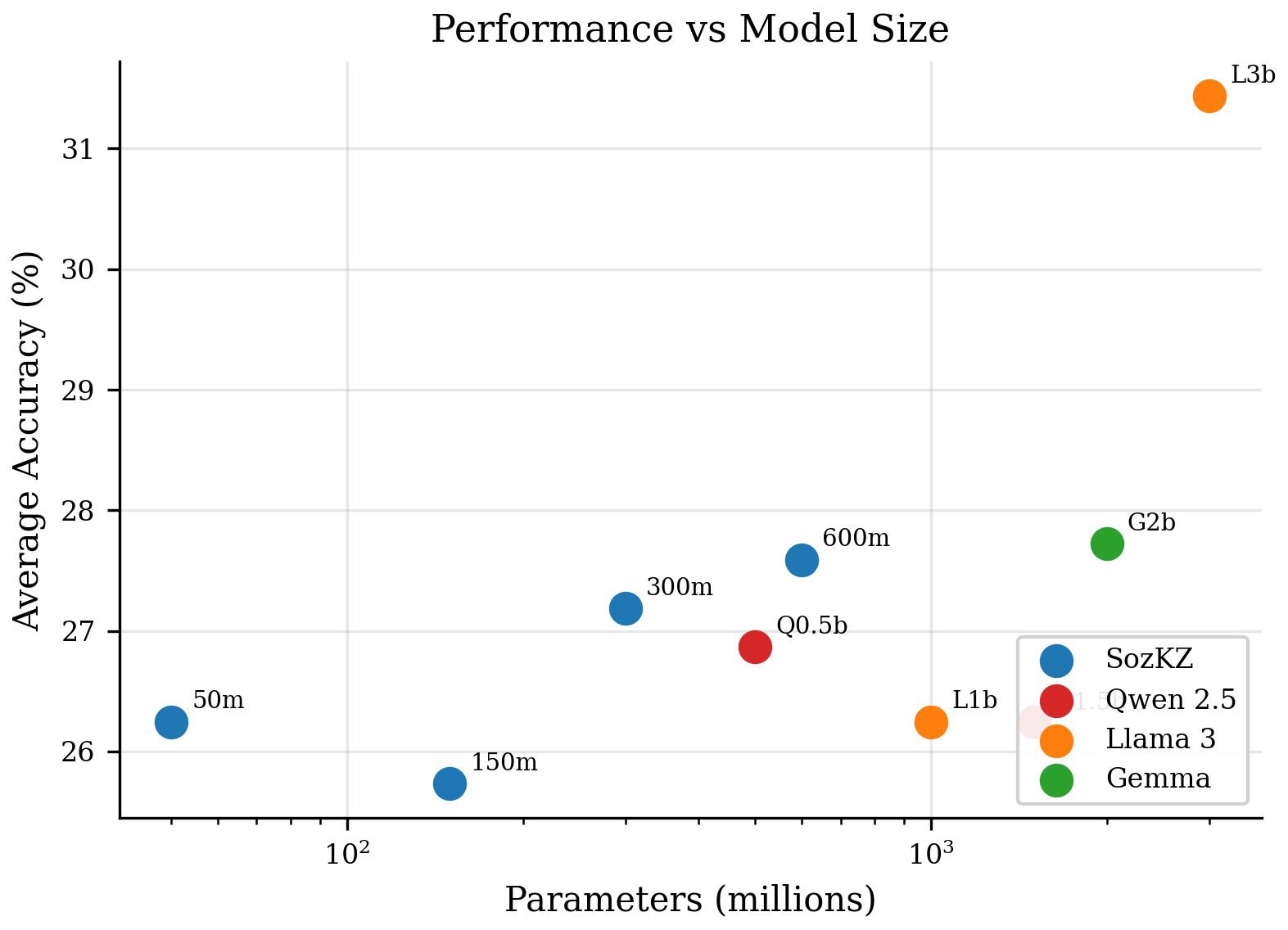
Kazakh, a Turkic language spoken by over 22 million people, remains underserved by existing multilingual language models, which allocate minimal capacity to low-resource languages and employ tokenizers ill-suited to agglutinative morphology. We present SozKZ, a family of Llama-architecture language models (50M–600M parameters) trained entirely from scratch on 9 billion tokens of Kazakh text with a dedicated 50K BPE tokenizer. We evaluate all models on three Kazakh benchmarks — multiple-choice cultural QA, reading comprehension (Belebele), and topic classification (SIB-200) — alongside five multilingual baselines ranging from 500M to 3B parameters. Our 600M model achieves 30.3% accuracy on Kazakh cultural QA, approaching the 32.0% of Llama-3.2-1B (2× larger), and 25.5% on SIB-200 topic classification, surpassing all evaluated multilingual models up to 2B parameters. These results demonstrate that small, dedicated models trained from scratch with a language-appropriate tokenizer offer a viable path for low-resource language technology. All models and the tokenizer are released under open licenses.
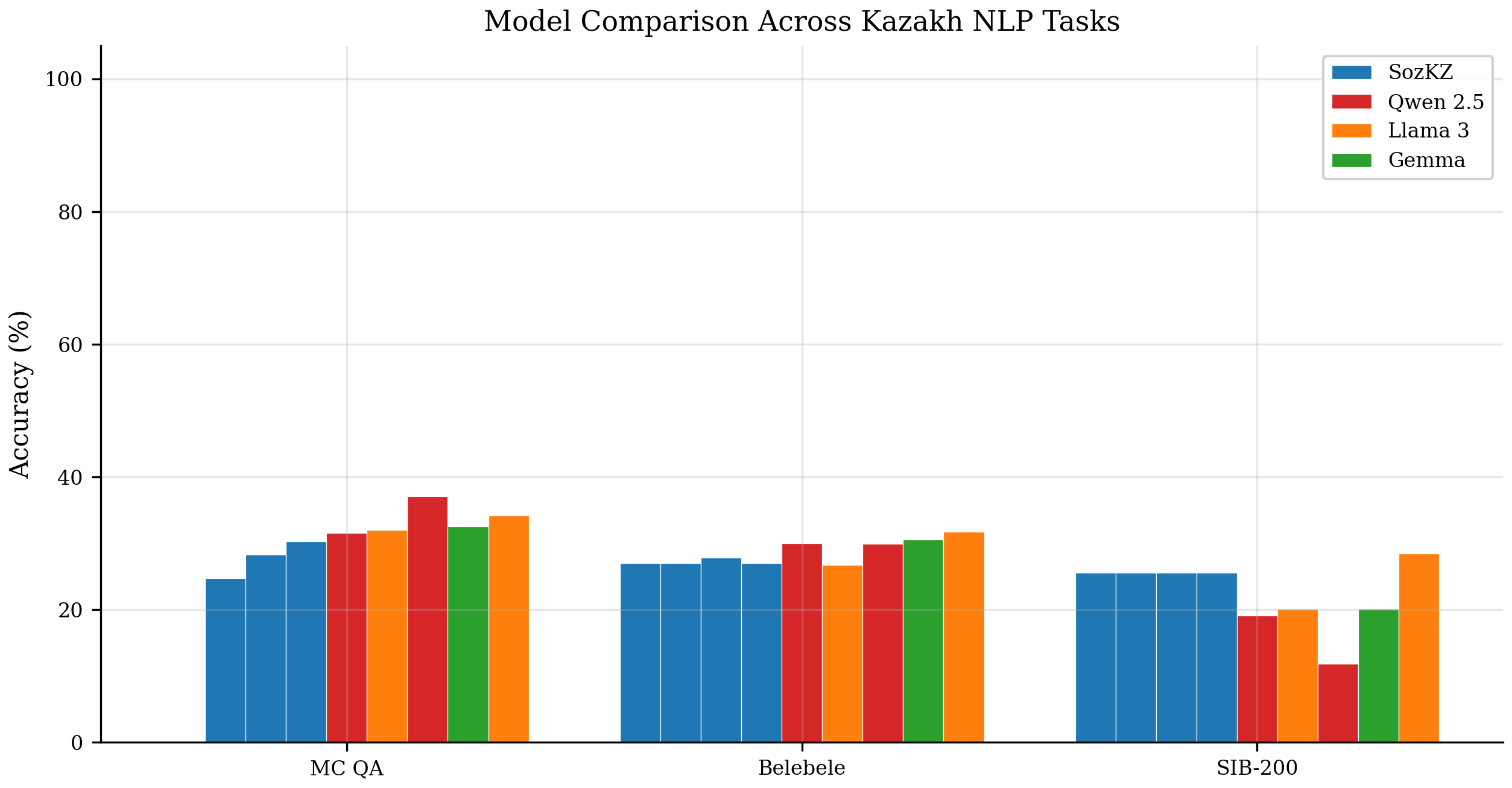
Accuracy (%) on three Kazakh benchmarks. Random baselines: MC QA = 25% (4-choice), Belebele = 25% (4-choice), SIB-200 = 14.3% (7-class).
| Model | Params | MC QA | Belebele | SIB-200 |
|---|---|---|---|---|
| SozKZ-50M | 50M | — | 27.0 | 25.5 |
| SozKZ-150M | 150M | 24.7 | 27.0 | 25.5 |
| SozKZ-300M | 300M | 28.3 | 27.8 | 25.5 |
| SozKZ-600M | 600M | 30.3 | 27.0 | 25.5 |
| Qwen-0.5B | 500M | 31.5 | 30.0 | 19.1 |
| Llama-3.2-1B | 1B | 32.0 | 26.7 | 20.1 |
| Qwen-1.5B | 2B | 37.1 | 29.9 | 11.8 |
| Gemma-2B | 2B | 32.5 | 30.6 | 20.1 |
| Llama-3.2-3B | 3B | 34.2 | 31.7 | 28.4 |
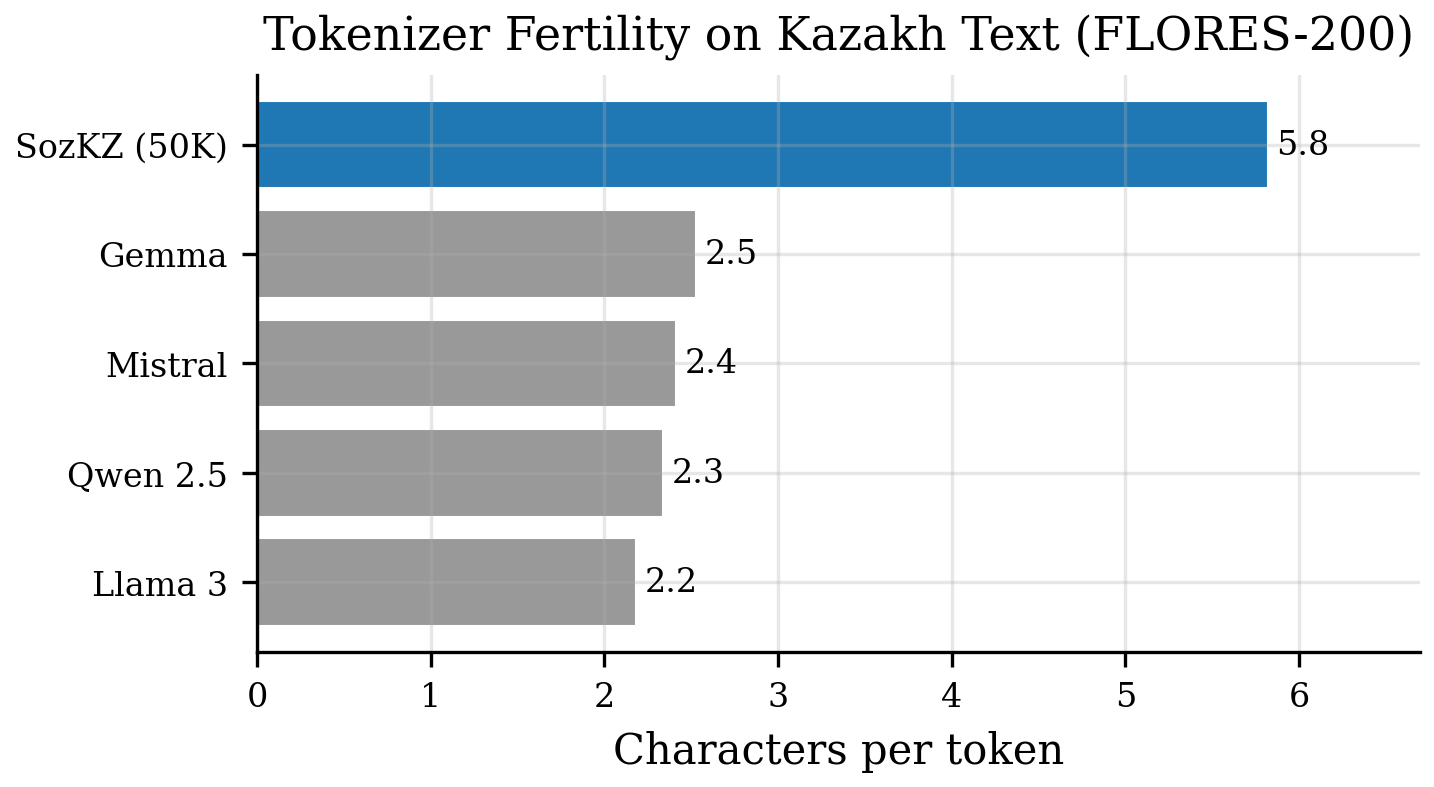
Characters per token on Kazakh text — higher is better.
| Tokenizer | Vocab Size | Chars/Token |
|---|---|---|
| SozKZ (50K) | 50,000 | 5.82 |
| Gemma | 256,000 | 2.53 |
| Mistral | 32,768 | 2.41 |
| Qwen 2.5 | 151,936 | 2.34 |
| Llama 3 | 128,256 | 2.18 |